Muy buenas a todos,
Hoy os quiero contar los pasos que he dado para usar en mis proyectos de Visual Studio 2013 bower, usándolo como gestor de paquetes en el lado del cliente, y grunt, como task runner. Ambos están siendo muy comúnmente usados en el mundo del desarrollo de aplicaciones web y si bien, la versión de Visual Studio 2015 los incluye de forma nativa, podemos configurar nuestros proyectos web de Visual Studio 2013 para usar estas dos herramientas tan útiles.
Para todo aquel que le pueda interesar, dejo la entrada del blog en la que me he basado para hacer toda la configuración, aunque si accedéis veréis que en el post, se usa otro gestor de tareas llamado gulp en lugar de grunt.
http://blogs.msdn.com/b/cdndevs/archive/2015/02/17/using-bower-with-visual-studio-2013.aspx
Pero antes de entrar en detalle, vamos a ver qué son exactamente cada una de estas herramientas.
¿Qué es Bower?
Bower works by fetching and installing packages from all over, taking care of hunting, finding, downloading, and saving the stuff you’re looking for.
La primera pregunta que se nos plantea viendo lo que hace Bower es ¿Y Nugget?. La respuesta a esta pregunta es muy sencilla. Desde su aparición Nugget se ha descubierto como una herramienta muy eficaz para la gestión de paquetes de servidor, pero no así para paquetes de cliente. Bower se ha convertido en el estándar de facto en el desarrollo web. Es poco probable, que un desarrollador que crea una nueva librería en Javascript la ponga disponible como paquete Nugget, sin embargo es frecuente que esté disponible en Bower en todas sus versiones. Esto provoca desactualización o imposibilidad de usar determinadas librerías a través de Nugget, lo que desaconseja su uso como herramientas de gestión de paquetes del lado del cliente.
¿Qué es Grunt?
In one word: automation. The less work you have to do when performing repetitive tasks like minification, compilation, unit testing, linting, etc, the easier your job becomes.
En resumen, con Grunt vamos a poder automatizar determinadas tareas que van a ayudar a tener nuestra aplicación lista para poner en producción con acciones como: minimizar y agrupar los estilos, minimizar y agrupar los javascript, etc. En la entrada veremos una tarea que he creado que puede ser necesaria y recomendable cuando usamos Bower.
Configurando y usando Bower
Para la configuración de Bower, podéis fácilmente seguir la entrada del blog de la msdn sin ningún problema, es muy sencilla de seguir y está muy detallada, de hecho yo la he seguido y es lo que de forma simplificada explicaré por aquí, solo hay una cosa que cambia, porque a mi al menos, o no me quedaba claro en la entrada inicial o no estaba debidamente reflejado. Vamos a ello.
- El primer paso es instalar node.js, ya que tanto Bower como Grunt lo utilizan. Enlace de descarga de node.js
- A continuación, abrimos la línea de comandos e instalamos bower
npm install bower -g
- Tras esto, necesitaremos tener instalado Git, Bower utiliza Git para descargar los paquetes. Concretamente instalaremos msysgit. Durante la instalación, tendremos que seleccionar la opción que vemos en la imagen a continuación para que se realice toda la configuración correctamente

- Ya tenemos listo Bower para ser utilizado. Si lo vamos a usar dentro de un proyecto de MVC, antes tendremos que tener en cuenta que por defecto, la plantilla de este tipo de proyectos en Visual Studio incluye una serie de paquetes, entre ellos: bootstrap, jquery, modernizr, etc. Por lo que antes de comenzar a usar bower en nuestro proyecto, tenemos que desinstalarlos. Para ello accedemos a la consola de Nuget y ejecutamos el siguiente comando para cada uno de los paquetes
Uninstall-Package <package>
Ahora que ya tenemos listo Bower vamos a usarlo dentro de nuestro proyecto. Esto lo haremos a través de la línea de comandos. En mi caso, no he usado la interfaz de línea de comandos propia de Windows (cmd), ya que me daba errores al usarla con Bower y Git, y buscando por internet vi que recomendaban usar una interfaz de línea de comandos que se instala con msysgit. Esta es Git Bash.
Vamos ahora a entrar al directorio del proyecto, y comenzaremos con el uso de Bower. Lo primero que haremos será iniciar el fichero de configuración de Bower. Para ello ejecutamos:
bower init
Una vez creado el fichero bower.json, podemos comenzar a instalar paquetes, esto lo haremos de la siguiente forma.
bower install jquery --save
bower install polymer --save
Una Buena Práctica recomendada para el uso de los paquetes que se obtienen con Bower, es no agregar directamente todos los archivos descargados con Bower a nuestro proyecto, ya que los paquetes en muchas ocasiones contienen más archivos de los que realmente necesitaremos, por lo que se recomienda copiar al proyecto solo aquellos archivos que realmente sean necesarios. ¿Cómo hacemos esto, manualmente?. La respuesta evidentemente es no, para esto tenemos nuestro Task Runner, Grunt 😉
Configurando y usando Grunt
En primer lugar, para añadir el soporte a Grunt para nuestro proyecto vamos a crear dos ficheros que añadiremos a la raíz del mismo package.json y gruntfile.js. El fichero package.json inicialmente contendrá la siguiente información.
{
"name": "WebApplication1",
"version": "1.0.0",
"description": "WebApplication package project",
"main": "gruntfile.js",
"license": "ISC";
}
A continuación y como ejemplo, la tarea que vamos a crear va a copiar los ficheros necesarios de los paquetes que hemos obtenido mediante Bower a la carpeta Scripts, donde se encuentran los ficheros js de nuestro proyecto. El código del fichero gruntfile.js es el siguiente:
module.exports = function (grunt) {
grunt.initConfig({
copy: {
main: {
files: [
{
expand: true,
cwd: '../bower_components/webcomponentsjs/',
src: ['webcomponents.js'],
dest: 'Scripts'
},
{
expand: true,
cwd: '../bower_components/jquery/dist',
src: ['jquery.min.js'],
dest: 'Scripts'
}
]
}
}
});
grunt.loadNpmTasks('grunt-contrib-copy');
grunt.registerTask('build', ['copy']);
};
Obviamente, aún podríamos hacer algunas tareas de minimización y agrupamiento de ficheros con grunt y que serían necesarias, aunque eso lo dejo para más adelante, es posible que en alguna entrada futura os cuente como hacerlo.
Para que funcione correctamente, necesitamos un plugin de Grunt, «grunt-contrib-copy». Cuando necesitemos añadir determinados plugins para nuestras tareas de Grunt, lo haremos desde la línea de comandos usando la utilidad npm de node.js. Nos vamos al directorio del proyecto y ejecutamos el siguiente comando.
npm install grunt-contrib-copy --save-dev
Una vez que ya tenemos instalado el plugin, desde la línea de comandos en el directorio en el que está nuestro archivo gruntfile.js (la raíz del proyecto), ejecutamos grunt. Esto llevará a cabo la tarea que hemos creado. La primera vez que ejecutamos grunt, tendremos que añadir manualmente los archivos que se han añadido a la tarea al proyecto, aunque esta acción no tendremos que volver a hacerla.
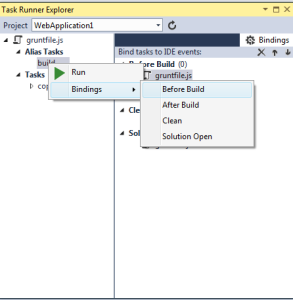
Como hemos visto, hasta ahora estamos usando la línea de comando para ejecutar Grunt. Pero, ¿Y si queremos que se ejecute automáticamente Grunt cuando hacemos el deploy del proyecto, esto es posible?, la respuesta es si. Para esto tenemos varias extensiones de Visual Studio que nos lo permiten. En mi caso he utilizado Task Runner Explorer.
La descargamos y la instalamos y ya podremos usarla en nuestro Visual Studio 2013. Vamos a View->Other Windows->Task Runner Explorer y cuando se abre la nueva ventana, lo primero que hacemos es pulsar sobre el botón actualizar para que capture todas las tareas creadas si aún no lo habia hecho.

Aquí vemos que podemos configurar si queremos que una determinada tarea se ejecute antes del deploy de la solución, con lo que podremos automatizar correctamente la ejecucion de Grunt y no tendremos que hacerlo manualmente a través de la línea de comandos.

Os dejo para terminar, algunos enlaces más de utilidad relacionado con lo que hemos visto en la entrada:
http://gruntjs.com/
http://bower.io/
https://visualstudiogallery.msdn.microsoft.com/8e1b4368-4afb-467a-bc13-9650572db708
Y esto es todo por hoy, yo a partir de ahora voy a utilizar estas dos herramientas en todos mis proyectos, por las ventajas que ofrecen, espero que todos podáis hacerlo.
Un saludo y hasta la próxima




















